��。為此�����,研究者針對這一新任務(wù)專門建立了 Video Story 數(shù)據(jù)集�����。該數(shù)據(jù)集包含四種常見而復雜的事件(生日�、露營、圣誕����、婚禮),通過關(guān)鍵字檢索從 Youtube 上檢索下載���,最后手動選擇 105 個在事件內(nèi)部和不同事件之間都有足夠差異性的視頻�����。這些視頻的故事通過亞馬遜勞務(wù)眾包平臺 Amazon Mechanical Turk 收集����。故事的選擇必須滿足以下三個條件:(1)至少包含 8 個句子����;(2)每個句子至少包含 6 個單詞;(3)故事內(nèi)容要連貫����,并合視頻內(nèi)容契合。最后研究者請工作人員針對每個故事中每個句子����,標注其在視頻中的開始時間和結(jié)束時間����。最終�,研究者收集了 529 個故事。

圖|Video Story 與其他現(xiàn)存數(shù)據(jù)集的比較���。
研究者在新數(shù)據(jù)集上對新模型和目前效果最好的模型進行了評估和比較���,新模型均取得了更優(yōu)的結(jié)果。
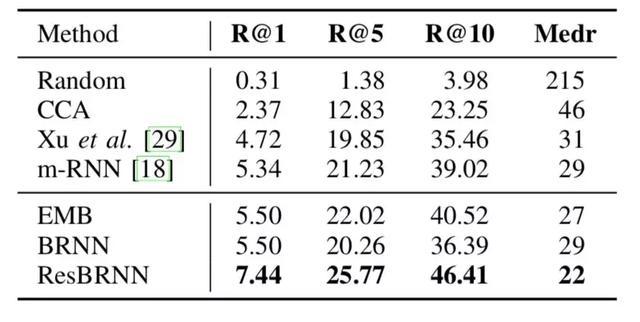
圖|多模態(tài)嵌入評估:以一系列視頻片段作為查詢條件����,檢索得到一個句子序列。R@K 的數(shù)值越高��,Medr 的數(shù)值越低表示效果越好
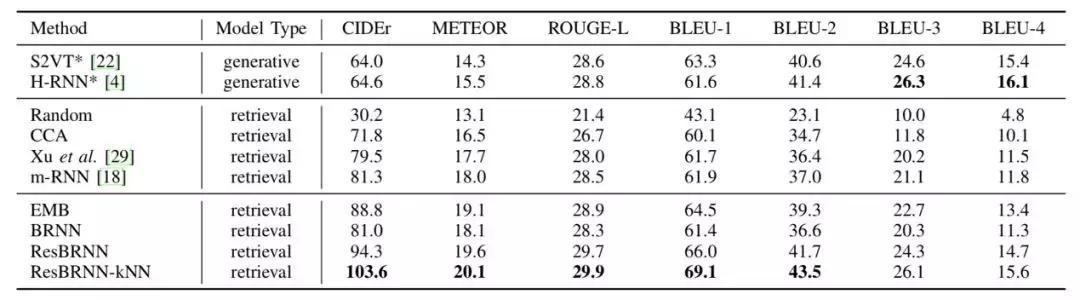
圖|Video Story 數(shù)據(jù)集上�,確定視頻片段條件下不同模型的故事生成結(jié)果評估。ResBRNN-KNN 優(yōu)勢明顯���。
圖|Video Story 數(shù)據(jù)集上的故事生成評估結(jié)果(針對對模型第二部分)�����。實驗中�����,視頻片段由各個模型自行提取���,根據(jù)視頻片段檢索句子的方式固定。Narrator(旁白模型)各項指標均效果更佳���。
不過����,該模型目前還有很大的局限性�。例如,生成故事的句子只能在數(shù)據(jù)集中檢索�����。研究者表示���,在接下來的工作中�,他們將使用更多野生的句子來擴展故事的多樣性���,同時使用一些自然語言處理的方法使句子之間的的銜接更加自然��。
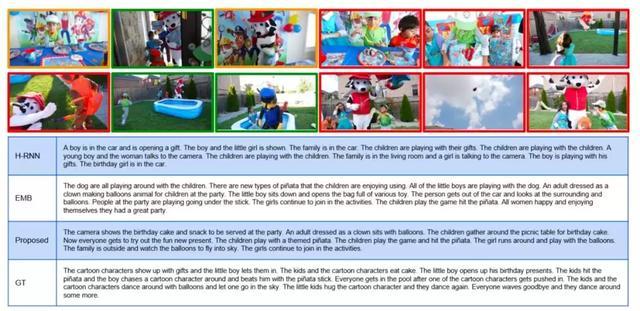
圖|不同模型生成的故事舉例�����。Proposed 為研究者提出的新模型���,GT 為作為參照的標準答案�。綠色框為 GT 選擇的重要視頻片段����,黃色框新模型選擇的重要視頻片段。紅色框為二者共同選中的視頻片段��。